La última versión de la aplicación de escritorio ofrece herramientas de desarrollo y controles de modelos mejorados, así como un mejor rendimiento para las GPU RTX.
A medida que los casos de uso de IA continúan expandiéndose (desde el resumen de documentos hasta agentes de software personalizados), los desarrolladores y entusiastas buscan formas más rápidas y flexibles de ejecutar modelos de lenguaje grandes ( LLM ).
La ejecución local de modelos en PC con GPU NVIDIA GeForce RTX permite inferencia de alto rendimiento, mayor privacidad de datos y control total sobre la implementación e integración de la IA. Herramientas como LM Studio (de prueba gratuita) lo hacen posible, ofreciendo a los usuarios una forma sencilla de explorar y desarrollar con LLM en su propio hardware.
LM Studio se ha convertido en una de las herramientas más utilizadas para la inferencia LLM local. Basada en el entorno de ejecución de alto rendimiento llama.cpp , la aplicación permite la ejecución de modelos completamente sin conexión y también puede servir como punto final de interfaz de programación de aplicaciones (API) compatible con OpenAI para su integración en flujos de trabajo personalizados.
El lanzamiento de LM Studio 0.3.15 ofrece un rendimiento mejorado para las GPU RTX gracias a CUDA 12.8, lo que mejora significativamente la carga del modelo y los tiempos de respuesta. La actualización también incorpora nuevas funciones para desarrolladores, como un uso mejorado de las herramientas mediante el parámetro « tool_choice» y un editor de mensajes del sistema rediseñado.
Las últimas mejoras de LM Studio optimizan su rendimiento y usabilidad, ofreciendo el mayor rendimiento hasta la fecha en PC con IA RTX. Esto se traduce en respuestas más rápidas, interacciones más ágiles y mejores herramientas para desarrollar e integrar IA localmente.
Donde las aplicaciones cotidianas se encuentran con la aceleración de la IA
LM Studio está diseñado para ofrecer flexibilidad, ideal tanto para experimentación casual como para la integración completa en flujos de trabajo personalizados. Los usuarios pueden interactuar con los modelos mediante una interfaz de chat de escritorio o habilitar el modo desarrollador para servir puntos finales de API compatibles con OpenAI. Esto facilita la conexión de LLM locales a flujos de trabajo en aplicaciones como VS Code o agentes de escritorio personalizados.
Por ejemplo, LM Studio se puede integrar con Obsidian , una popular aplicación de gestión del conocimiento basada en Markdown. Mediante complementos desarrollados por la comunidad, como Text Generator y Smart Connections , los usuarios pueden generar contenido, resumir investigaciones y consultar sus propias notas, todo ello con la tecnología de LLM locales que se ejecutan en LM Studio. Estos complementos se conectan directamente al servidor local de LM Studio, lo que permite interacciones de IA rápidas y privadas sin depender de la nube.

La actualización 0.3.15 agrega nuevas capacidades para desarrolladores, incluido un control más granular sobre el uso de herramientas a través del parámetro “ tool_choice” y un editor de indicaciones del sistema mejorado para manejar indicaciones más largas o más complejas.
El parámetro tool_choice permite a los desarrolladores controlar cómo interactúan los modelos con herramientas externas, ya sea forzando una llamada a la herramienta, deshabilitándola por completo o permitiendo que el modelo tome decisiones dinámicas. Esta mayor flexibilidad es especialmente valiosa para crear interacciones estructuradas, flujos de trabajo de generación aumentada por recuperación ( RAG ) o pipelines de agentes. En conjunto, estas actualizaciones mejoran los casos de uso de experimentación y producción para los desarrolladores que crean con LLM.
LM Studio admite una amplia gama de modelos abiertos, incluidos Gemma, Llama 3, Mistral y Orca, y una variedad de formatos de cuantificación, desde 4 bits hasta precisión completa.
Los casos de uso comunes incluyen RAG, chat multiturno con largas ventanas de contexto, preguntas y respuestas basadas en documentos y flujos de trabajo de agentes locales. Además, al usar servidores de inferencia locales con la tecnología de la biblioteca de software llama.cpp acelerada por NVIDIA RTX, los usuarios de PC con IA RTX pueden integrar fácilmente LLM locales.
Ya sea para optimizar la eficiencia en un sistema compacto con tecnología RTX o para maximizar el rendimiento en un escritorio de alto rendimiento, LM Studio ofrece control total, velocidad y privacidad, todo en RTX.
Experimente el máximo rendimiento en las GPU RTX
La aceleración de LM Studio se basa en llama.cpp, un entorno de ejecución de código abierto diseñado para una inferencia eficiente en hardware de consumo. NVIDIA se asoció con las comunidades de LM Studio y llama.cpp para integrar diversas mejoras y maximizar el rendimiento de la GPU RTX.
Las optimizaciones clave incluyen:
- Habilitación de gráficos CUDA: agrupa múltiples operaciones de GPU en una sola llamada de CPU, lo que reduce la sobrecarga de la CPU y mejora el rendimiento del modelo hasta en un 35 %.
- Atención flash en kernels CUDA : Aumenta el rendimiento hasta en un 15 % al mejorar el procesamiento de la atención por parte de los LLM, una operación crítica en los modelos de transformadores. Esta optimización permite ventanas de contexto más largas sin aumentar los requisitos de memoria ni de cómputo.
- Compatibilidad con las últimas arquitecturas RTX: la actualización de LM Studio a CUDA 12.8 garantiza la compatibilidad con la gama completa de PC con IA RTX, desde GeForce RTX Serie 20 hasta GPU NVIDIA Blackwell, lo que brinda a los usuarios la flexibilidad de escalar sus flujos de trabajo de IA locales desde computadoras portátiles hasta computadoras de escritorio de alta gama.

Con un controlador compatible, LM Studio se actualiza automáticamente al entorno de ejecución CUDA 12.8, lo que permite tiempos de carga de modelos significativamente más rápidos y un mayor rendimiento general.
Estas mejoras brindan una inferencia más fluida y tiempos de respuesta más rápidos en toda la gama de PC con RTX AI, desde computadoras portátiles delgadas y livianas hasta computadoras de escritorio y estaciones de trabajo de alto rendimiento.
Comience a usar LM Studio
LM Studio se puede descargar gratis y funciona en Windows, macOS y Linux. Con la última versión 0.3.15 y las optimizaciones continuas, los usuarios pueden esperar mejoras continuas en rendimiento, personalización y usabilidad, lo que hace que la IA local sea más rápida, flexible y accesible.
Los usuarios pueden cargar un modelo a través de la interfaz de chat del escritorio o habilitar el modo de desarrollador para exponer una API compatible con OpenAI.
Para comenzar rápidamente, descargue la última versión de LM Studio y abra la aplicación.
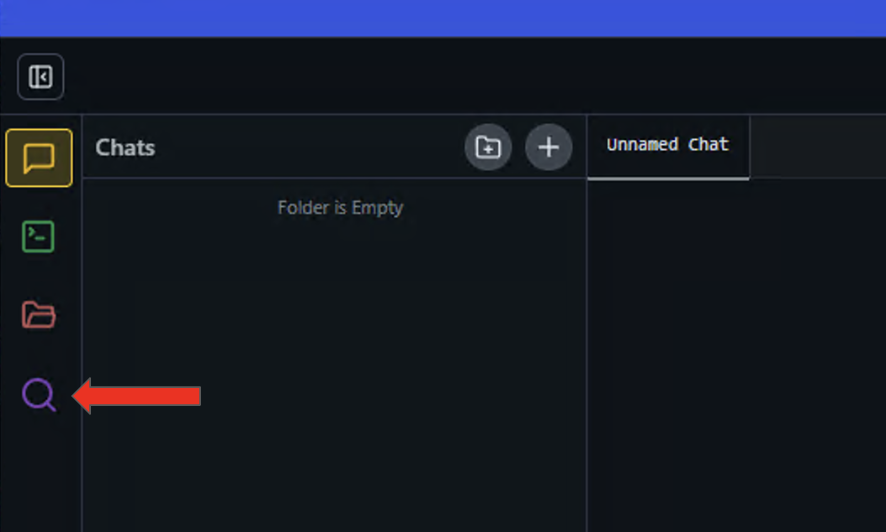
- Haga clic en el icono de la lupa en el panel izquierdo para abrir el menú Descubrir .
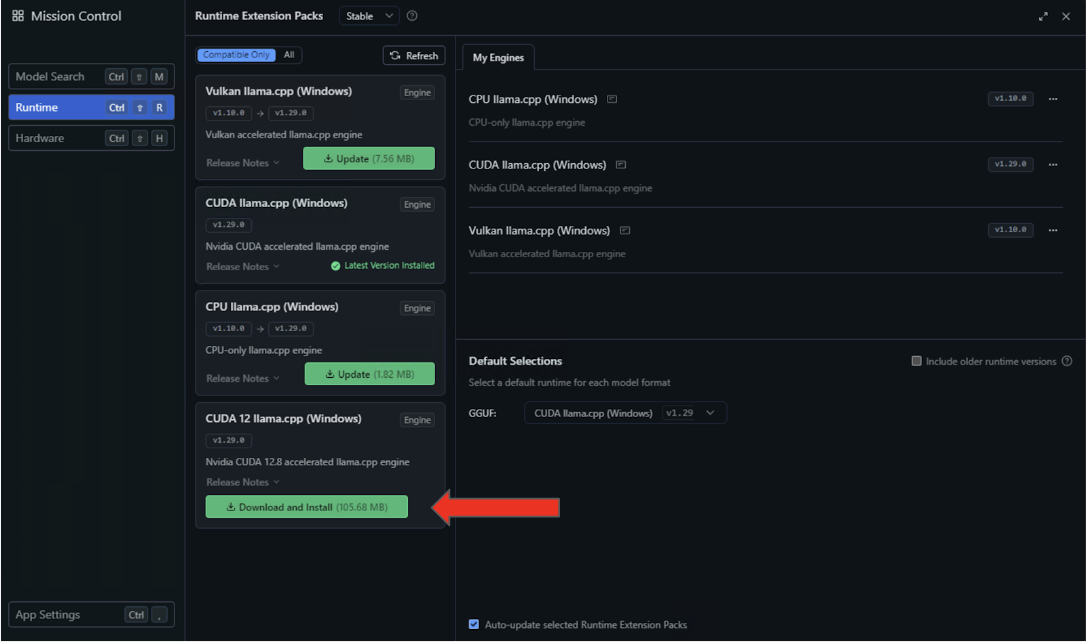
- Seleccione la configuración del entorno de ejecución en el panel izquierdo y busque el entorno de ejecución CUDA 12 llama.cpp (Windows) en la lista de disponibilidad. Seleccione el botón «Descargar e instalar».
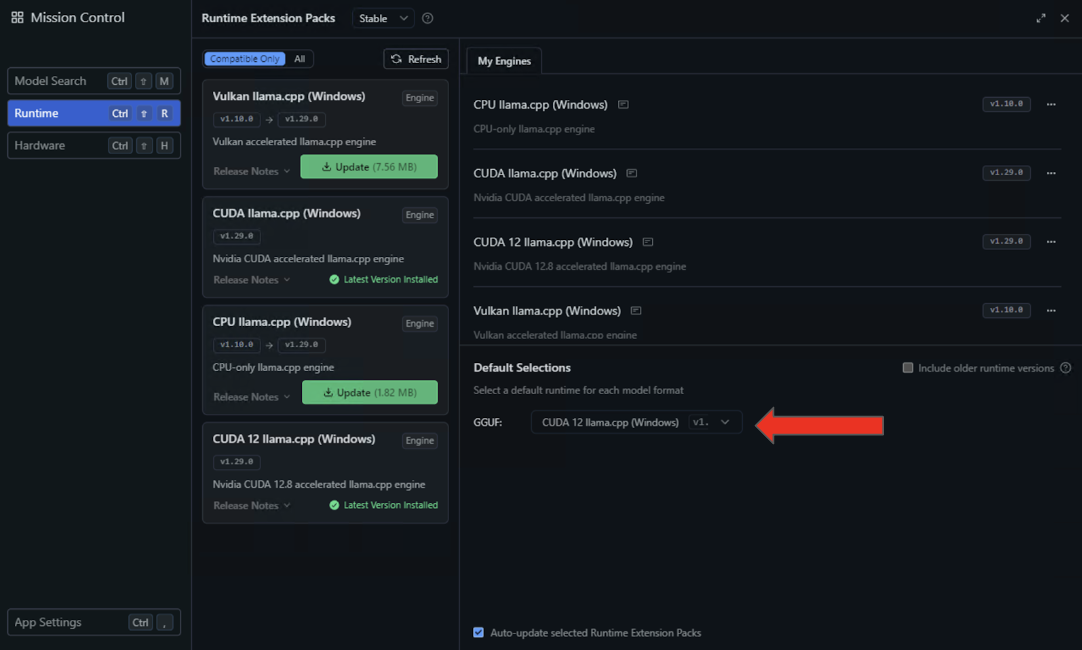
- Una vez completada la instalación, configure LM Studio para utilizar este entorno de ejecución de forma predeterminada seleccionando CUDA 12 llama.cpp (Windows) en el menú desplegable Selecciones predeterminadas.
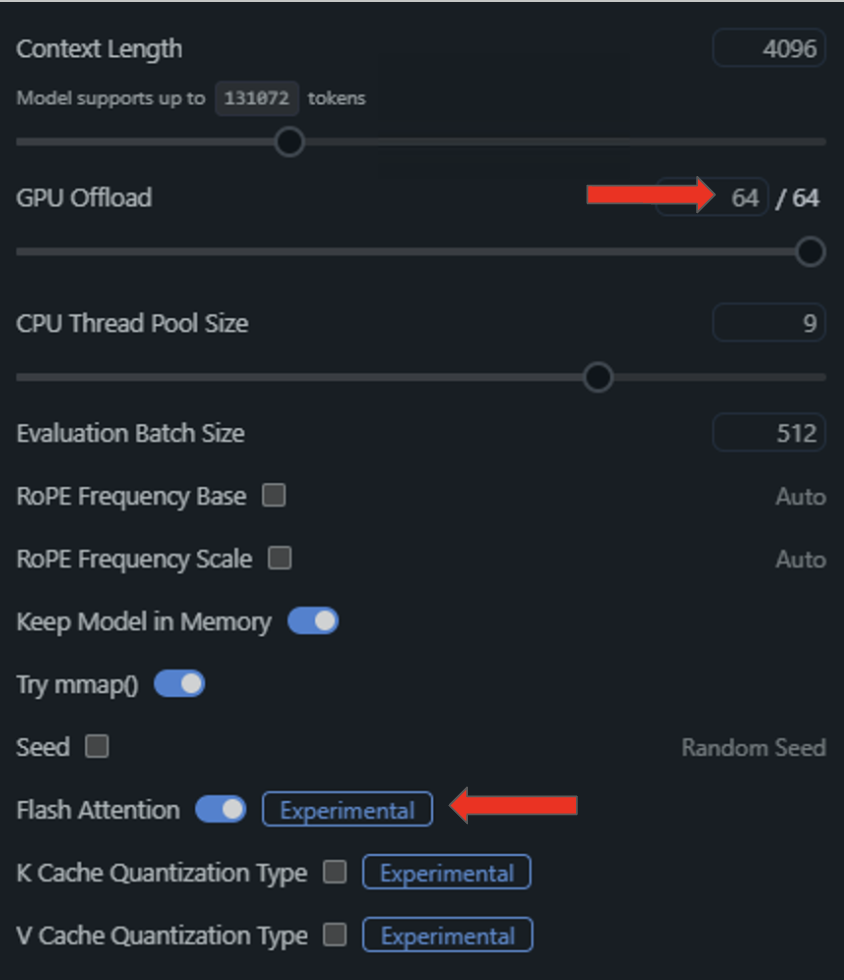
- Para los pasos finales en la optimización de la ejecución de CUDA, cargue un modelo en LM Studio e ingrese al menú Configuración haciendo clic en el ícono de engranaje a la izquierda del modelo cargado.
- En el menú desplegable resultante, active “Flash Attention” y descargue todas las capas del modelo en la GPU arrastrando el control deslizante “GPU Offload” hacia la derecha.
Una vez que estas funciones estén habilitadas y configuradas, ya está listo para ejecutar la inferencia de GPU NVIDIA en una configuración local.
LM Studio admite ajustes preestablecidos de modelo, diversos formatos de cuantificación y controles para desarrolladores como tool_choice para una inferencia precisa. Para quienes deseen contribuir, el repositorio de GitHub llama.cpp se mantiene activo y continúa evolucionando con mejoras de rendimiento impulsadas por la comunidad y NVIDIA.
Cada semana, la serie de blogs RTX AI Garage presenta innovaciones y contenido de IA impulsados por la comunidad para aquellos que buscan aprender más sobre los microservicios NVIDIA NIM y los AI Blueprints , así como también sobre la creación de agentes de IA , flujos de trabajo creativos, humanos digitales, aplicaciones de productividad y más en PC y estaciones de trabajo de IA. NVIDIA Blog. Traducido al español

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}