Mi recorrido en la creación de un bot de voz para producción
El mundo de la inteligencia artificial está repleto de innovaciones, y una de sus ramas más fascinantes es el desarrollo de bots de voz. Estas entidades digitales tienen el poder de transformar las interacciones de los usuarios, volviéndolas más naturales e intuitivas. En esta publicación del blog, quiero llevarte a un viaje a través de mi experiencia en la creación de un bot de voz desde cero utilizando las tecnologías de vanguardia de Azure: OpenAI GPT-4o-Realtime, Azure Text-to-Speech (TTS) y Speech-to-Text (STT).
https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2FoZtWPST-xUo%3Ffeature%3Doembed&display_name=YouTube&url=https%3A%2F%2Fwww.youtube.com%2Fshorts%2FoZtWPST-xUo&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2FoZtWPST-xUo%2Fhqdefault.jpg&type=text%2Fhtml&schema=youtube
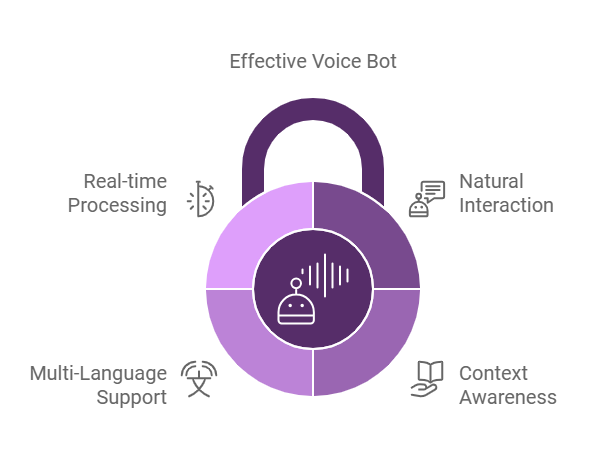
Características clave para crear un bot de voz eficaz
- Interacción natural : la capacidad de un agente de voz para conversar de forma natural es fundamental. El objetivo es crear interacciones que reflejen una conversación humana, evitando respuestas robóticas o predefinidas. Este naturalismo fomenta la comodidad del usuario, lo que genera una experiencia más fluida y atractiva.
- Conocimiento del contexto : la verdadera sofisticación de un agente de voz proviene de su capacidad para comprender el contexto y retener información. Esta capacidad le permite brindar respuestas y acciones personalizadas en función del historial del usuario, sus preferencias y consultas específicas.
- Compatibilidad con varios idiomas : uno de los obstáculos más importantes para desarrollar un agente de voz integral es la necesidad de compatibilidad con varios idiomas. A medida que las marcas atienden a diversos mercados, es fundamental garantizar una comunicación clara y contextualmente precisa en todos los idiomas.
- Procesamiento en tiempo real : las capacidades en tiempo real de los agentes de voz permiten respuestas inmediatas, lo que mejora la experiencia del cliente. Esta característica es fundamental para tareas como reservas, compras y consultas en las que la urgencia es importante.
Además, existen inmensas oportunidades disponibles. Si se implementa con éxito, un agente de voz sólido puede revolucionar la interacción con el cliente. Considere un escenario en el que una empresa utiliza un agente de voz impulsado por IA para llegar a clientes potenciales en una campaña de marketing. Este enfoque puede mejorar enormemente la eficiencia, lo que permite a la empresa gestionar grandes volúmenes de clientes potenciales y proporcionar un retorno de la inversión enormemente mejorado en comparación con los métodos tradicionales.
Antes de sumergirnos en los aspectos técnicos, es fundamental tener una visión clara de lo que se quiere lograr con el bot de voz. En mi caso, el objetivo era crear un bot que pudiera entablar conversaciones fluidas con los usuarios, comprender sus necesidades y brindar respuestas oportunas. Imaginé un bot que pudiera integrarse en varias plataformas, ofreciendo flexibilidad y adaptabilidad. Azure ofrece un conjunto sólido de herramientas para el desarrollo de IA, y elegirlo fue una decisión fácil debido a sus ofertas integrales y sus sólidas capacidades de integración. Así es como comencé:
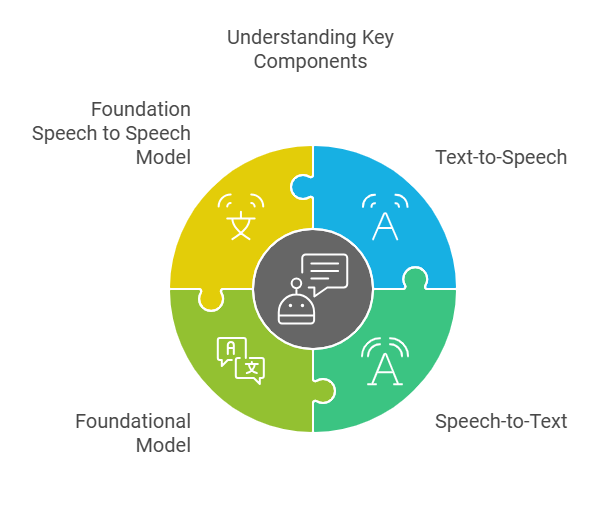
- Texto a voz (TTS): este servicio convertiría las respuestas de texto del bot en un habla similar a la de un humano. Azure TTS ofrece una variedad de voces personalizables, lo que me permitió elegir una que coincidiera con la personalidad del bot.
- Speech-to-Text (STT): para comprender las entradas del usuario, el bot necesitaba convertir el lenguaje hablado en texto. Azure STT fue fundamental para lograrlo, ya que proporciona transcripción en tiempo real con gran precisión.
- Modelo fundamental: se refiere a un modelo de lenguaje amplio (LLM) que potencia la comprensión del lenguaje por parte del bot y la generación de respuestas de texto. Algunos ejemplos de modelos fundamentales son: GPT-4: un LLM potente desarrollado por OpenAI, capaz de generar texto de calidad humana, traducir idiomas, escribir distintos tipos de contenido creativo y responder a sus preguntas de forma informativa.
- Modelo básico de conversión de voz a voz: podría referirse a un modelo que traduce directamente el habla de un idioma a otro, sin necesidad de texto como paso intermedio. Este modelo podría utilizarse para la traducción en tiempo real o para generar voz en un idioma distinto del idioma de entrada.
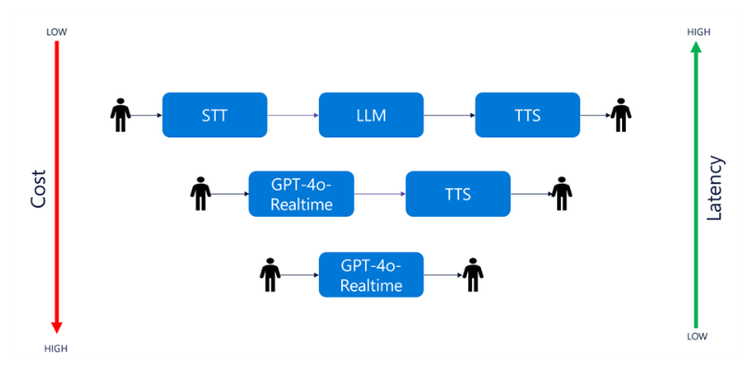
A medida que la tecnología de voz continúa evolucionando, han surgido diferentes tipos de bots de voz para satisfacer las distintas necesidades de los usuarios. En este análisis, exploraremos tres tipos destacados: Voice Bot Duplex , GPT-4o-Realtime y GPT-4o-Realtime + TTS . Esta comparación detallada cubrirá su arquitectura, fortalezas, debilidades, mejores prácticas, desafíos y posibles oportunidades de implementación.
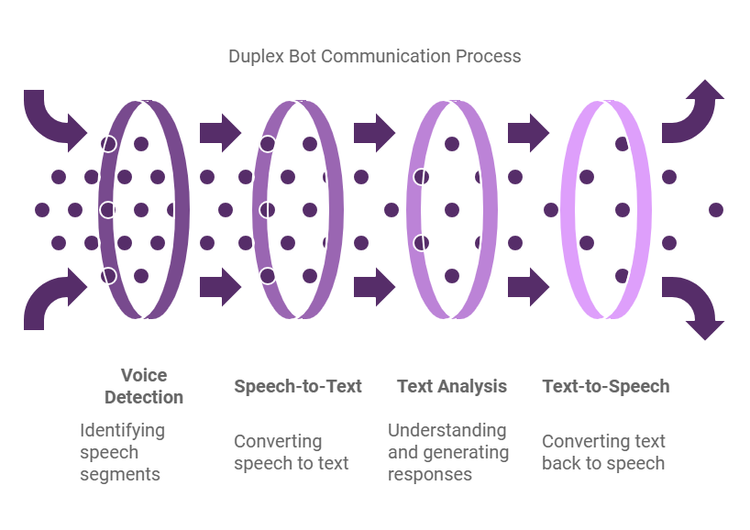
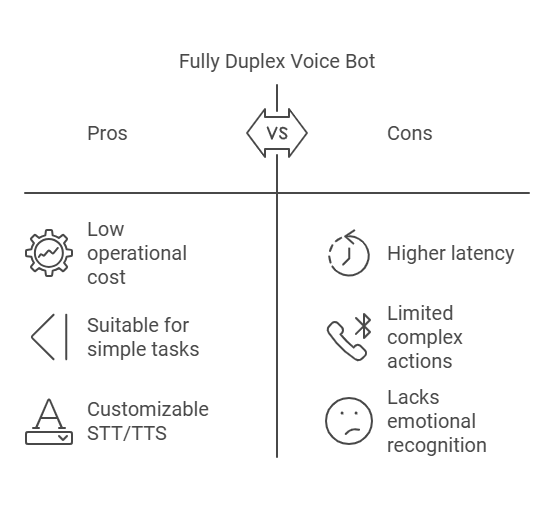
Tipo 1: Bot de voz Duplex:
Duplex Bot es un sistema de inteligencia artificial avanzado que lleva a cabo conversaciones telefónicas y completa tareas mediante detección de actividad de voz (VAD), conversión de voz a texto (STT), modelos de lenguaje grandes (LLM) y conversión de texto a voz (TTS). La tecnología de reconocimiento automático de voz (ASR) de Azure convierte el lenguaje hablado en texto. Un LLM analiza este texto para generar respuestas, que luego se convierten nuevamente en voz mediante Azure Text-To-Speech (TTS). Duplex Bot puede escuchar y responder simultáneamente, lo que mejora la fluidez de la interacción y reduce el tiempo de respuesta. Esta integración permite a Duplex gestionar de forma autónoma tareas como la reserva de citas con una mínima intervención humana.
– Fortalezas :
- Bajo costo operativo.
- Arquitectura compleja con múltiples saltos de procesamiento, lo que dificulta su implementación.
- Adecuado para casos de uso sencillos con requisitos de conversación básicos.
- Personalizable fácilmente tanto para el lado STT como para el TTS
– Debilidades :
- Mayor latencia en comparación con los modelos avanzados, lo que limita las capacidades en tiempo real.
- Capacidad limitada para realizar acciones complejas o mantener el contexto durante conversaciones largas.
- No capta la emoción humana del discurso.
- Cambiar de idioma durante una conversación es difícil. Para obtener un mejor resultado, hay que elegir el idioma de antemano.
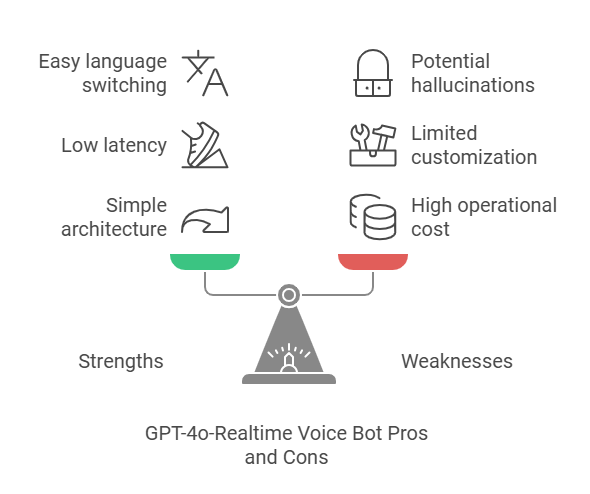
Tipo 2- GPT-4o-Tiempo real
Los robots de voz basados en GPT-4o-Realtime son los más simples de implementar, ya que utilizan el modelo de habla fundamental, ya que podría referirse a un modelo que toma directamente el habla como entrada y genera el habla como salida, sin la necesidad de texto como paso intermedio. La arquitectura es muy simple, ya que la matriz de voz va directamente al modelo de voz fundamental, que procesa esta matriz de bytes de voz, razona y responde al habla como matriz de bytes.
– Fortalezas :
- Arquitectura más simple sin saltos de procesamiento, lo que hace que sea más fácil de implementar.
- Baja latencia y alta confiabilidad
- Adecuado para casos de uso sencillos con requisitos de conversación complejos.
- Cambiar de idioma es muy fácil
- Capta la emoción del usuario.
– Debilidades :
- Alto costo operacional.
- No puedes personalizar la voz sintetizada.
- No se puede agregar una abreviatura específica de la empresa al modelo para manejarlo por separado
- Alucino mucho al introducir números. Si dices el modelo 123456, a veces el modelo toma 123435.
La compatibilidad con diferentes idiomas puede ser un problema, ya que no existe documentación oficial sobre compatibilidad con idiomas específicos.
Tipo 3- GPT-4o-Tiempo real + TTS
Los robots de voz basados en GPT-4o-Realtime son los más simples de implementar, ya que utilizan el modelo de habla fundamental, ya que podría referirse a un modelo que toma directamente la voz como entrada y genera la voz como salida, sin la necesidad de texto como paso intermedio. La arquitectura es muy simple, ya que la matriz de voz va directamente al modelo de voz fundamental, que procesa esta matriz de bytes de voz, razona y responde con la voz como matriz de bytes. Pero si desea personalizar la síntesis de voz, no hay opciones de ajuste fino presentes para personalizarla. Por lo tanto, se nos ocurrió una opción en la que conectamos GPT-4o-Realtime con Azure TTS, donde tomamos la modulación de voz avanzada, como las voces neuronales integradas con una variedad de idiomas índicos, también puede ajustar una voz neuronal personalizada (CNV).
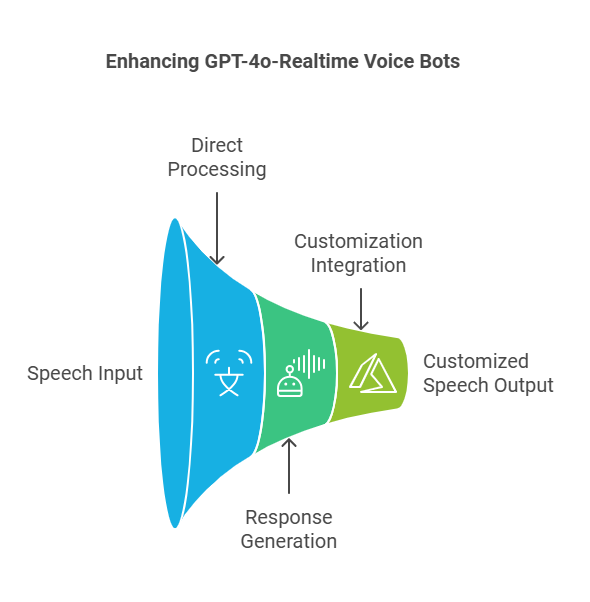
La voz neuronal personalizada (CNV) es una función de conversión de texto a voz que le permite crear una voz sintética personalizada y única para sus aplicaciones. Con la voz neuronal personalizada, puede crear una voz que suene muy natural para su marca o sus personajes proporcionando muestras de voz humana como datos de entrenamiento.
De fábrica, la conversión de texto a voz se puede utilizar con voces neuronales predefinidas para cada idioma compatible . Las voces neuronales predefinidas funcionan bien en la mayoría de los escenarios de conversión de texto a voz si no se requiere una voz única. La voz neuronal personalizada se basa en la tecnología de conversión de texto a voz neuronal y en el modelo universal multilingüe y multihablante. Puede crear voces sintéticas ricas en estilos de habla o adaptables a varios idiomas. La voz realista y de sonido natural de la voz neuronal personalizada puede representar marcas, personificar máquinas y permitir que los usuarios interactúen con las aplicaciones de manera conversacional. Consulte los idiomas compatibles con la voz neuronal personalizada.
– Fortalezas :
- Arquitectura simple con un solo salto de procesamiento, lo que hace más fácil su implementación.
- Baja latencia y alta confiabilidad
- Adecuado para casos de uso sencillos con requisitos de conversación complejos y voz personalizada.
- Cambiar de idioma es muy fácil
- Capta la emoción del usuario.
– Debilidades :
- Alto costo operativo pero aún inferior a GPT-4o-Realtime.
- No puede agregar una abreviatura específica de la empresa al modelo para manejarla por separado
- Alucino mucho al introducir números. Si dices el modelo 123456, a veces el modelo toma 123435.
- No admite frases personalizadas
Conclusión
La creación de un bot de voz es un proceso emocionante pero desafiante. Como hemos visto, aprovechar las herramientas avanzadas de Azure, como GPT-4o-Realtime, Text-to-Speech y Speech-to-Text, puede proporcionar la base para crear un bot de voz que comprenda, interactúe y responda con fluidez similar a la humana. A lo largo de este proceso, aspectos clave como la interacción natural, el conocimiento del contexto, la compatibilidad con varios idiomas y el procesamiento en tiempo real fueron vitales para garantizar la eficacia del bot en varios escenarios.
Si bien cada modelo de bot de voz, desde Voice Bot Duplex hasta GPT-4o-Realtime y GPT-4o-Realtime + TTS, ofrece sus fortalezas y debilidades, todos resaltan la importancia de considerar cuidadosamente las necesidades específicas de la aplicación. Ya sea que se apunte a conversaciones simples o interacciones más sofisticadas, la elección del modelo afectará directamente el rendimiento, el costo y la satisfacción general del usuario del bot.
De cara al futuro, el potencial de los bots de voz impulsados por IA es inmenso. Con los avances continuos en IA, los bots de voz seguramente se integrarán aún más en nuestra vida diaria, transformando la forma en que interactuamos con la tecnología. A medida que este campo siga evolucionando, la combinación de herramientas innovadoras y pensamiento estratégico será clave para desarrollar bots de voz que no solo cumplan con las expectativas de los usuarios, sino que las superen. Microsoft Blog. G. de M. R. Traducido la español

