KAIST (presidente Kwang Hyung Lee) anunció el 25 que un equipo de investigación dirigido por el profesor Jemin Hwangbo del Departamento de Ingeniería Mecánica desarrolló una tecnología de control de robot cuadrúpedo que puede caminar con robustez y agilidad incluso en terrenos deformables como una playa de arena.

< Foto. El equipo del laboratorio RAI con el profesor Hwangbo en el medio de la última fila. >
El equipo de investigación del profesor Hwangbo desarrolló una tecnología para modelar la fuerza que recibe un robot que camina sobre un suelo hecho de materiales granulares como arena y simularla a través de un robot cuadrúpedo. Además, el equipo trabajó en una estructura de red neuronal artificial que es adecuada para tomar decisiones en tiempo real necesarias para adaptarse a varios tipos de suelo sin información previa mientras camina al mismo tiempo y la aplicó al aprendizaje de refuerzo. Se espera que el controlador de red neuronal entrenado amplíe el alcance de aplicación de los robots cuadrúpedos que caminan al demostrar su robustez en terrenos cambiantes, como la capacidad de moverse a alta velocidad incluso en una playa de arena y caminar y girar en terrenos blandos como un colchón de aire sin perder el equilibrio.
Esta investigación, cuyo primer autor es el estudiante de doctorado Soo-Young Choi del Departamento de Ingeniería Mecánica del KAIST, se publicó en enero en la revista Science Robotics (título del artículo: Aprendizaje de la locomoción cuadrúpeda en terreno deformable).
El aprendizaje por refuerzo es un método de aprendizaje de IA que se utiliza para crear una máquina que recopila datos sobre los resultados de diversas acciones en una situación arbitraria y utiliza ese conjunto de datos para realizar una tarea. Debido a que la cantidad de datos necesarios para el aprendizaje por refuerzo es tan grande, se utiliza ampliamente un método de recopilación de datos a través de simulaciones que se aproximan a los fenómenos físicos en el entorno real.
En particular, los controladores basados en el aprendizaje en el campo de los robots caminantes se han aplicado a entornos reales después de aprender a través de datos recopilados en simulaciones para realizar con éxito controles de marcha en diversos terrenos.
Sin embargo, dado que el rendimiento del controlador basado en el aprendizaje disminuye rápidamente cuando el entorno real presenta alguna discrepancia con el entorno de simulación aprendido, es importante implementar un entorno similar al real en la etapa de recopilación de datos. Por lo tanto, para crear un controlador basado en el aprendizaje que pueda mantener el equilibrio en un terreno deformable, el simulador debe proporcionar una experiencia de contacto similar.
El equipo de investigación definió un modelo de contacto que predijo la fuerza generada al contacto a partir de la dinámica de movimiento de un cuerpo que camina basándose en un modelo de fuerza de reacción del suelo que consideró el efecto de masa adicional de los medios granulares definidos en estudios anteriores.
Además, al calcular la fuerza generada a partir de uno o varios contactos en cada paso de tiempo, se simuló de manera eficiente el terreno deformado.
El equipo de investigación también introdujo una estructura de red neuronal artificial que predice implícitamente las características del terreno mediante el uso de una red neuronal recurrente que analiza datos de series temporales de los sensores del robot.
El controlador aprendido se montó en el robot ‘RaiBo’, que fue construido por el equipo de investigación para demostrar que podía caminar a alta velocidad (hasta 3,03 m/s) en una playa de arena, donde los pies del robot estaban completamente sumergidos en la arena. Incluso cuando se aplicó en terrenos más duros, como campos de hierba y una pista de atletismo, pudo correr de manera estable al adaptarse a las características del terreno sin necesidad de programación adicional ni revisión del algoritmo de control.
Además, giraba con estabilidad a 1,54 rad/s (aproximadamente 90° por segundo) sobre un colchón de aire y demostró su rápida adaptabilidad incluso en situaciones en las que el terreno se volvía repentinamente blando.
El equipo de investigación demostró la importancia de proporcionar una experiencia de contacto adecuada durante el proceso de aprendizaje en comparación con un controlador que asumía que el suelo era rígido, y demostró que la red neuronal recurrente propuesta modifica el método de caminata del controlador de acuerdo con las propiedades del suelo.
Se espera que la metodología de simulación y aprendizaje desarrollada por el equipo de investigación contribuya a que los robots realicen tareas prácticas, ya que amplía el rango de terrenos en los que pueden operar varios robots caminantes.
El primer autor, Suyoung Choi, afirmó: “Se ha demostrado que proporcionar un controlador basado en el aprendizaje con una experiencia de contacto cercano con un terreno deformable real es esencial para su aplicación en terrenos deformables”. Añadió que “el controlador propuesto se puede utilizar sin información previa sobre el terreno, por lo que se puede aplicar a diversos estudios de marcha de robots”.
Esta investigación se llevó a cabo con el apoyo del Centro de Incubación y Financiamiento de Investigación de Samsung Electronics.

< Figura 1. Adaptabilidad del controlador propuesto a diversos entornos terrestres. El controlador, que aprendió de una amplia gama de simulaciones aleatorias de medios granulares, mostró adaptabilidad a diversos terrenos naturales y artificiales, y demostró capacidad para caminar a alta velocidad y eficiencia energética. >
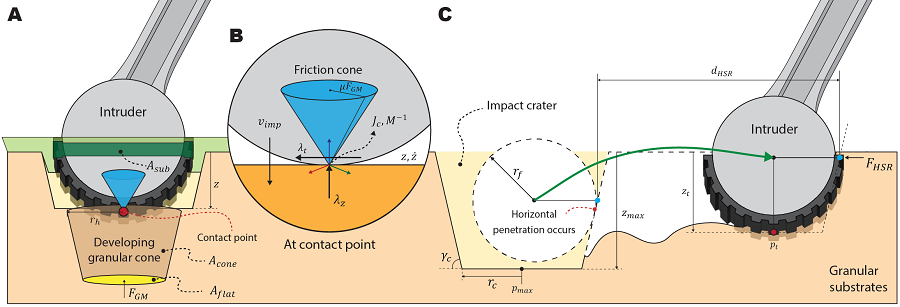
< Figura 2. Definición del modelo de contacto para la simulación de sustratos granulares. El equipo de investigación utilizó un modelo que consideraba el efecto de masa adicional para la fuerza vertical y un modelo de fricción de Coulomb para la dirección horizontal, mientras que aproximaba el contacto con el medio granular como si ocurriera en un punto. Además, se introdujo y utilizó para la simulación un modelo que simula la resistencia del suelo que puede ocurrir en el costado del pie. >
HAIST News. Traducido al español
